Using Naive Bayes in the
Classification of Spam Email
Team Members: Aspen Tng, Damien Snyder, Yadi Wang, Thai Quoc Hoang
Overview
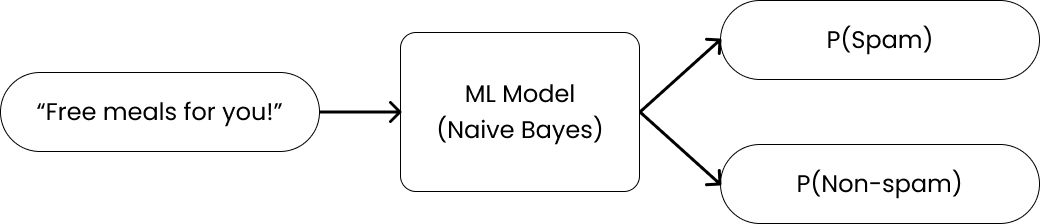
This article is a step-by-step guide on how to create a (very simplified) Machine Learning model to classify spam emails using Bayes Theorem as the core of the model.
The task
Under the hood, we have have a list of emails that are already labeled by spam/non-spam. We want to use this existing list of emails as data to predict whether an unseen email is spam or not.
Assumptions
This simplified model
1. ignores punctuations
2. ignores repeating words
3. treats all words to be conditional independent
Architecture of machine
In order to create such a machine, we need these following components:

a. What is an ML model?
For simplification, we can think of an ML model as a model artifact that is created in the way that it can "learn" the patterns of the data given to it during a training process. In this example, our ML model is the core component to classify whether an email is spam or non-spam.
b. Training data
The training data used in our example is the list of emails that was previously labelled. This data will be fed into our ML model for the machine to learn its patterns.
c. Intelligence
Finally, intelligence refers to the final product obtained by training the ML model with the training data. This intelligence can look at any "unseen"/new email and give a prediction on whether it should be classified as a spam or not. The quality of the intelligence is strongly influenced by the ML model and the training data.
Let's get started!